EDIT: 2-11-16. Oopsies, I caught a glitch in the code for Dr. Power. I popped in corrected figures and changed some interpretations throughout. My bad.

and......go!
I like statistically significant results. I like to find them. I like to read about them. I like them even more when they come from adequately powered studies.
I also have a lot of ideas. Most of them are probably garbage. I hope some of them are good. And it would be even cooler if some of the good ones were also right (p < .05, which we all know means you are most definitely right! Right?).
So, how should I go about doing research to maximize my number of good, right ideas (the kind that are easy to publish...I'm lazy like that)?
There's been a ton of push in social psych lately to beef up our power. We should be running bigger studies (yes, even bigger than 25 per condition). It actually takes more like 100 per condition to have good power for most of our effects. Yup, 200 per study for a 2 group design. Get 200 or go home. This is great advice...but is there another way?
In response to calls for more power, I've seen some voicing concerns that running fewer and fewer, but bigger and bigger, studies will unnecessarily slow science down. We'll be testing fewer ideas! We could more efficiently be exploring our world! And intuitively, this makes sense. I have limited resources. Why should I put all my eggs in a few baskets, rather than look everywhere for the damn eggs!
Cast a wide net?

One proposed way to find lots of eggs and eat cake too (to mix metaphors) would be to run lots of little underpowered studies on lots of ideas, then follow up the promising results with bigger replications. Cast a wide net initially, then pick a few winners and proceed with the empowering of the science. Jenna Jewell, Maxine Najle, Ben Ng, and I favorably discussed this strategy as potentially useful in a paper about power and incentives:
[can we all win by] consciously and explicitly treating individual underpowered studies as merely suggestive and exploratory, but pairing them in multi-study packages with adequately powered replications. That is, a researcher may conduct a number of underpowered studies to test novel ideas or to use costly methods. Of those that produce significant results, some could then be replicated (directly when cost allows, conceptually for difficult methods) in adequately powered designs.
Here's the catch: we actually had no clue if this strategy was a good idea. Intuitively it sounded good, so we rolled with it.
I decided to actually look into the viability of this strategy in some simulations. What do the results say? Should we initially cast wide (but underpowered) nets, or just cut to the chase and run adequately powered studies in the first place?
The simulations
I wanted to compare the "wide net" strategy to one in which researchers just run adequately powered studies from the outset. So I ran some simulations of these two strategies. Being a social psychologist, these simulations are extremely social-psych-centric.
Imagine two researchers running labs. When they have effects, they're typical for social psych (d = .4). They're not very creative, so they run two group, between subject designs.
- Dr. Wide Net runs lots of studies with 25 per condition. When he gets a statistically significant result on one of these (in the "right" direction, an important caveat), he preregisters it and runs an exact replication with 100 per condition.
- Dr. Power just aims for power for the outset. She runs experiments with 100 participants per condition. All day. Every day.
I assumed that they each run about 4000 participants per year. So they repeat their respective strategies until they burn 4000 subjects. Then I counted two things:
- How many ideas do they test? This is just the number of studies run for Dr. Power. For Dr. Wide Net, it's the number of initial small studies run (with additional participants being burned when a small study is significant).
- How many findings do they generate? That is, how many statistically significant "final" results do they get (Dr. Wide Net never publishes the initial small studies...they're just fodder for picking which big studies to run).
Now, some ideas are safe (have a high prior probability of the null hypothesis actually being false) and some are riskier (lower prior probability of H0 being false). So I simulated how things would go for each esteemed researcher across a variety of different prior probabilities (.1, .25, .5, .75, .9). I simulated 1000 "years" for each researcher, at each of these prior probabilities.
The results
What gives? Does it actually make sense to cast a wide net with small studies and use this to decide which studies to run with appropriate power?
Maybe not. Don't believe me? Here's a table:
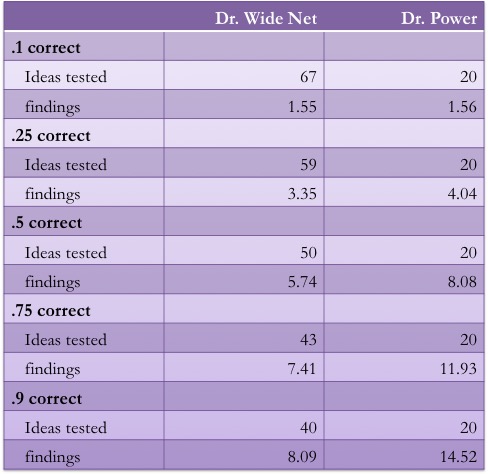
This is the average yearly yield from each researcher, in terms of ideas tested and significant "final" results generated. Matching intuitions, Dr. Wide Net gets to test a LOT more ideas. 2 to 3.4 times as many initial ideas get tested in Dr. Wide Net's lab each year.
But here's the weird thing...Dr. Wide Net doesn't consistently generate more well-supported findings! Dr. Wide Net is no more productive with risky ideas (1.55 to 1.56 findings per year). And as soon as half of their respective ideas are right, Dr. Power begins to dominate. This despite only running 20 studies per year.
It looks like the Wide Net strategy doesn't provide all that much bang for the buck. Sure, Dr. Wide Net gets to test a whole lot of ideas. But the low power of initial studies means that the vast majority of studies run are basically inconclusive noise. Even though Dr. Power tests relatively few ideas, the tests themselves are stronger from the get-go, yielding similar-to-superior rates of generating actual findings. And if we can assume that it takes time and resources to get studies up and launched, it looks like Dr. Power is spending less time coding things in Inquisit, writing scripts for RAs, analyzing data, etc.
I'm a pretty lazy dude. And maybe I'm right half of the time (if you ask my grad students, they'll tell you it's far, far lower. But they are cretins and liars). But I'd take 8 findings in 20 studies over 5.74 findings in 50 studies any day.
Now of course, maybe this wasn't realistic. Does Dr. Wide Net really just walk away from every initial study that turns up a pesky p = .064? Doubtful. So I re-ran the simulations with a twist: this time, Dr. Wide Net replicates (with adequate power) any initial study with a "marginal" effect (p < .1). What happens? Table time.
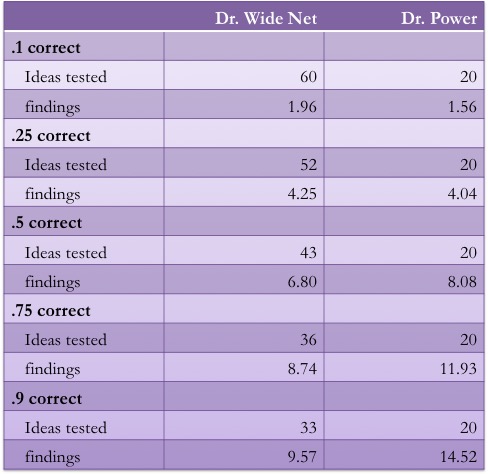
That's a little better, but the Wide Net strategy is still no savior. The returns are modest for risky ideas, but vanish by the time hypotheses are right half of the time or better. And the rate of return is still pretty poor. At prior probability = .5, only 16% of the ideas tested ever gain solid support. Compare this to 40% for Dr. Power. At prior probability = .75, Dr. Wide Net finds support for 24% of the ideas he tests, while Dr. Power supports around 60% of the ideas she tests.
Take home message?
So, is it a good idea to cast a wide net? Maybe not. Is it a super bad idea to cast a wide net? Maybe not.
But it definitely doesn't look like a clearly superior strategy to just running adequately powered studies in the first place. And it sure does look time consuming to run all those noninformative initial studies. Not exactly what you want from a strategy that seems like it would make the search for Good, Right ideas easier. For now, I think I'll stick with just doing the studies well in the first place.

Yup, here's the code. All the functions are up top and you can tinker with the inputs at the bottom. It's probably just as ugly and clunky as all my code, but it seems to work.
postscript...
Steve Spencer suggested maybe using p = .2 as the cutoff for initial small explorations. That sounded like a good idea, so I ran the simulations again with a more inclusive alpha. Here are the results:

Not bad! Especially for those riskier ideas. Dr. Wide Net could generate 44% more findings for shot-in-the-dark ideas (prior = .1). There's still the issue of time management, as the 44% more findings result from 2.5 times as many ideas tested. 2.5 times as much IRB, coding, RA training, and data analysis.
One important caveat: in all of these examples so far, the decision on which small studies to replicate with power depends on the studies meeting a given alpha threshold (p < .05, .1, or .2) and being in the right direction. But I suspect some of us (read: me) would occasionally find a significant (at whatever chosen alpha) result in a counterintuitive direction and think "holy shit, this could be something cool!" and then replicate it in a bigger sample. So what happens if the choice on which small studies to replicate is independent of the effect's direction?

In this case, some of the benefits begin to wash out. Dr. Wide Net is starting to spend more time chasing more noise. At prior=.5, Dr. Wide Net is running about twice as many studies to generate fewer findings. At prior=.1, Dr. Wide Net runs twice as many studies to generate 15% more findings. Not sure that's what I call "efficiency." But if the total number of significant findings is the main goal (no matter the blood, sweat, and tears to grad students and RAs and IRB people), Dr. Wide Net may help out for those improbable ideas.
Recommendation: a little ambiguous. But leaning heavily towards Dr. Power.